
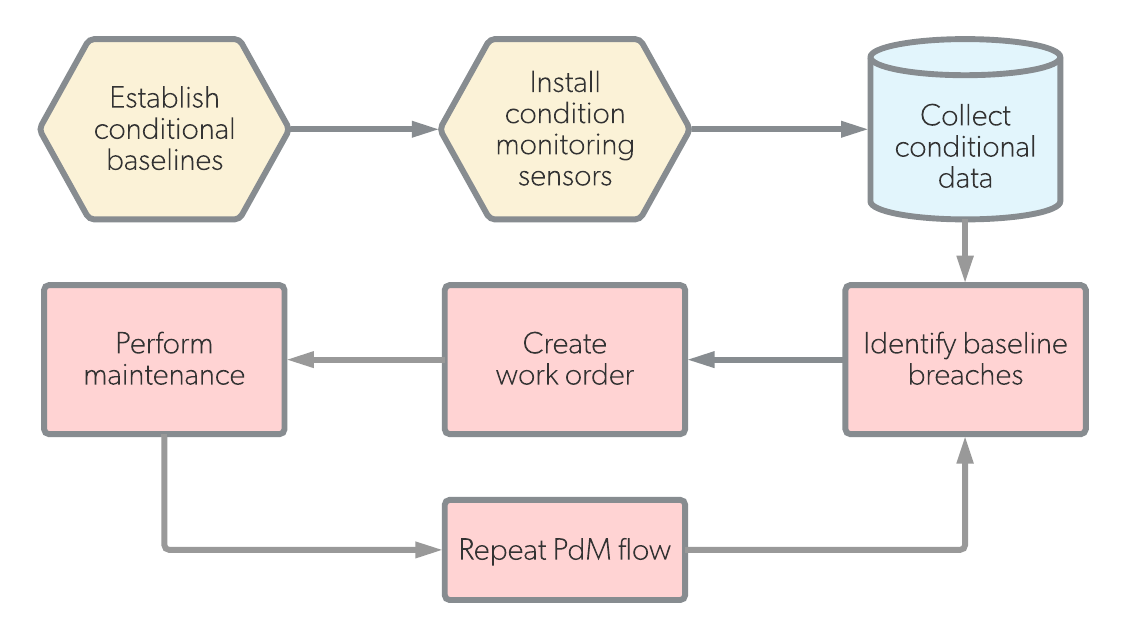
Predictive Maintenance System for Manufacturing
Built machine learning–based predictive maintenance platform that analyzes real-time sensor data from manufacturing equipment to detect early signs of mechanical failure. The system processes time-series data from more than 500 industrial sensors using advanced feature engineering including rolling statistics and frequency analysis.
Using ensemble models combining Random Forest, XGBoost and LSTM architectures, the platform predicts equipment failure up to 3–7 days in advance. Real-time ingestion is powered by Apache Kafka streams, while the prediction engine exposes REST APIs with confidence scores and automated alerting. The solution achieved 92% prediction accuracy and reduced unplanned downtime by 40%.
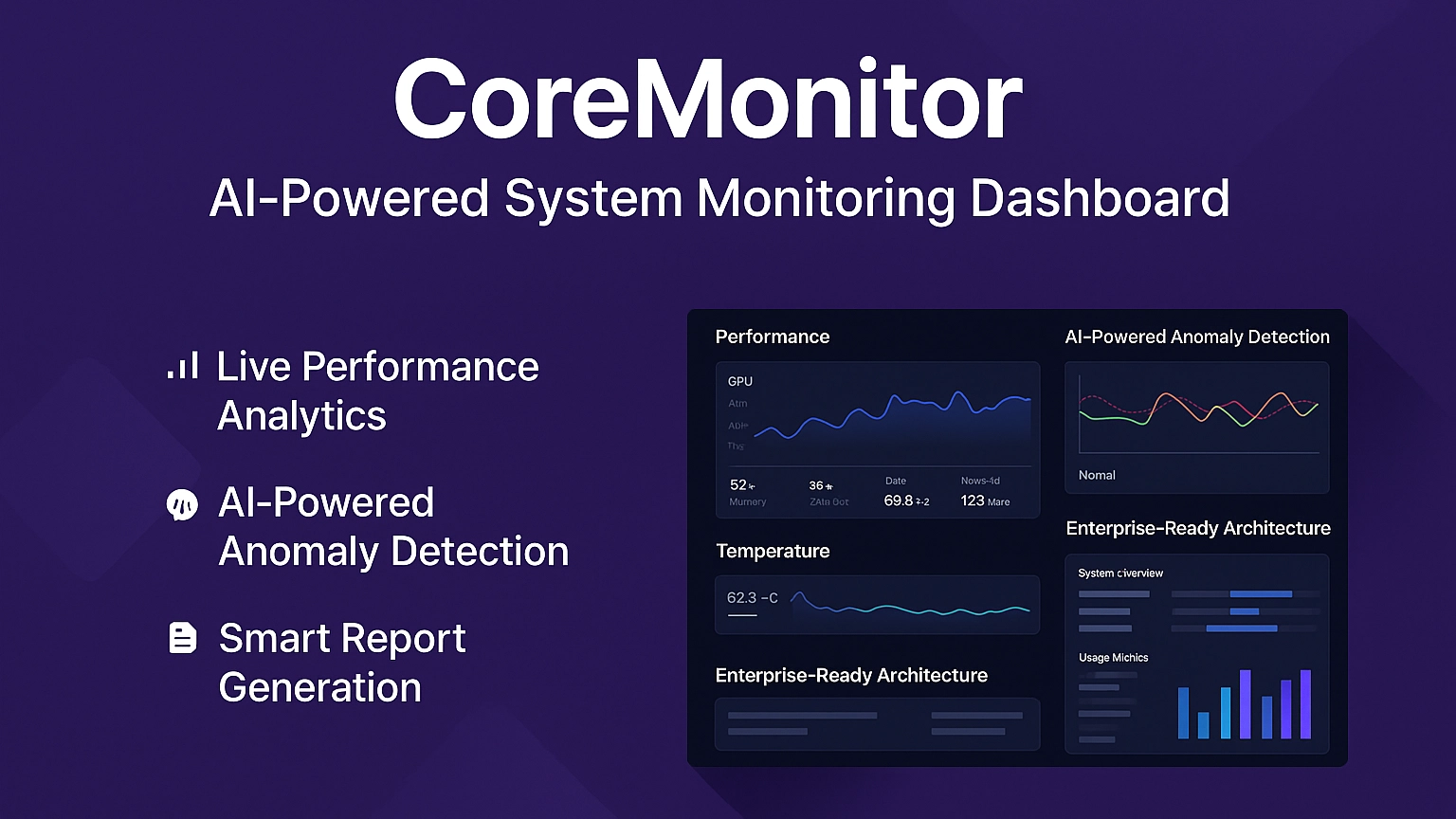
Enterprise AI Dashboard & Model Performance Monitoring
Developed enterprise AI monitoring dashboard enabling organizations to visualize machine learning model performance, data quality metrics and operational KPIs in real time. The system supports 10,000+ daily users with secure role-based access and interactive analytics dashboards.
The platform tracks key metrics including accuracy, precision, recall, F1-score and prediction confidence distributions while also monitoring model drift and system performance. Integrated alerting, A/B testing analytics and model version comparisons allow teams to continuously optimize model deployments and ensure production reliability across AI-driven applications.