
Generative AI systems have evolved rapidly over the last few years. However, as adoption has increased, organizations have discovered that language models alone are not reliable enough for real-world use. Because of this, Retrieval-Augmented Generation (RAG) has become a foundational architecture for modern AI systems.
In 2026, RAG architecture is no longer optional. Instead, it is the standard approach for building AI systems that are accurate, explainable, and scalable. Moreover, as enterprises demand higher trust and control, RAG architecture has become central to production-grade AI design.
This article explains RAG architecture in detail, including how it works, why it matters, and how modern systems implement it effectively.
What Is RAG Architecture?
RAG architecture is a system design pattern that combines information retrieval with language model generation. Instead of relying only on a model’s internal training data, a RAG system retrieves relevant information from external data sources before generating a response.
In other words, RAG separates knowledge storage from reasoning. As a result, AI systems can produce answers that are grounded in real, up-to-date data rather than assumptions.
Therefore, RAG architecture significantly reduces hallucinations while improving accuracy and trust.
Why RAG Architecture Became Necessary
Initially, large language models appeared powerful enough to answer almost any question. However, over time, several limitations became clear.
For example, traditional LLM systems:
- Contain static knowledge frozen at training time
- Cannot access private or proprietary data
- Often generate confident but incorrect answers
Because of these issues, organizations needed a way to connect models to real data. Consequently, RAG architecture emerged as the most practical solution.
Moreover, regulatory and enterprise requirements made it essential to explain where answers come from. As a result, RAG architecture gained widespread adoption.
High-Level RAG Architecture Flow

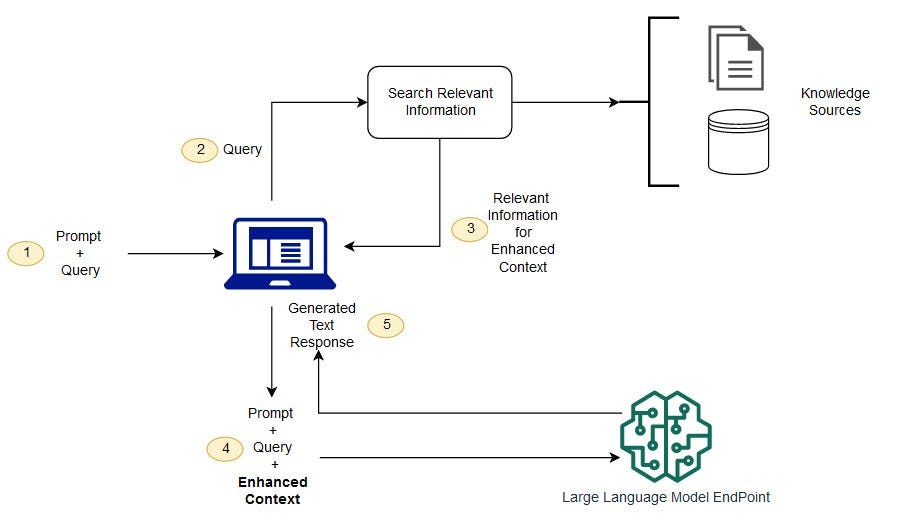
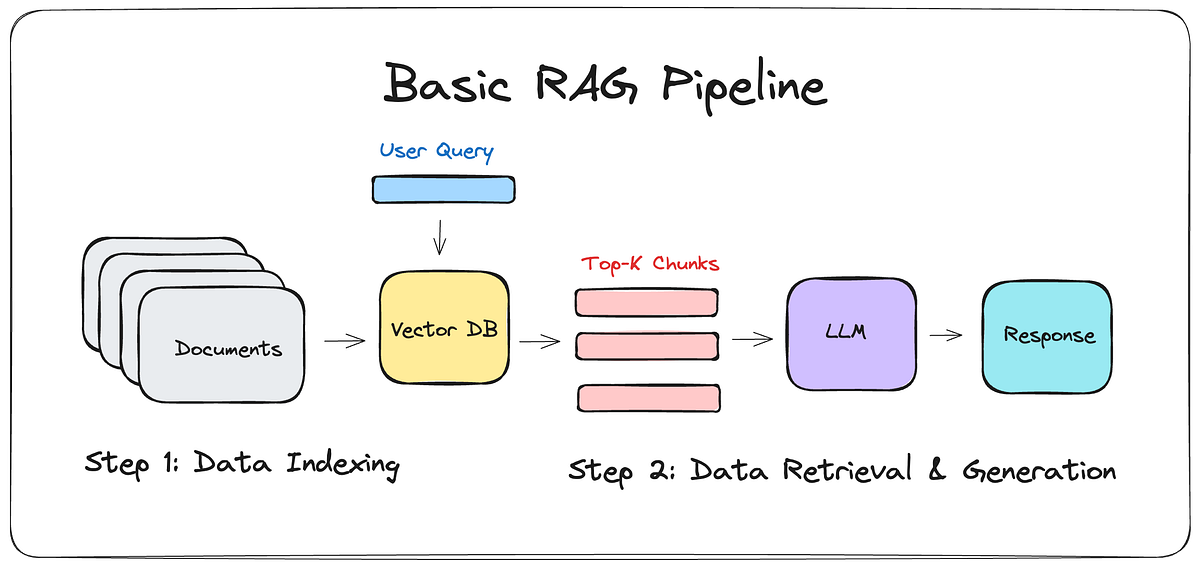
At a high level, a modern RAG system follows a structured flow:
- A user submits a query
- The system analyzes the query intent
- Relevant data is retrieved from external sources
- Retrieved results are ranked and filtered
- Selected context is injected into the prompt
- The language model generates a response
- The response may be validated or post-processed
Thus, instead of a single-step generation, RAG architecture introduces controlled, multi-stage processing.
Core Components of RAG Architecture
1. Data Sources Layer
First of all, RAG systems rely on external data. These data sources provide the factual grounding required for accurate answers.
Common sources include:
- Documents such as PDFs and HTML pages
- Databases (SQL or NoSQL)
- Knowledge bases and internal wikis
- APIs and structured services
Therefore, the quality of a RAG system depends heavily on the quality and structure of its data sources.
2. Ingestion and Indexing Pipeline
Next, raw data must be prepared before it can be retrieved efficiently. Because raw documents are rarely model-ready, an ingestion pipeline is required.
Typically, this pipeline performs:
- Text extraction
- Chunking of large documents
- Metadata enrichment
- Embedding generation
- Indexing for fast search
As a result, data becomes searchable, structured, and retrieval-ready.
3. Retrieval Layer
After data is indexed, the retrieval layer becomes responsible for finding relevant information.
In modern RAG architecture, retrieval may include:
- Keyword-based search for precision
- Semantic (vector) search for meaning
- Hybrid retrieval combining both
Therefore, retrieval strategies are chosen based on query type rather than a one-size-fits-all approach.
4. Ranking and Filtering Layer
However, raw retrieval results are rarely perfect. Because of this, a ranking and filtering layer is required.
This layer:
- Ranks results by relevance
- Removes duplicate content
- Filters outdated or low-quality data
- Applies access control rules
Consequently, only high-quality context reaches the language model.
5. Context Assembly Layer
Once relevant content is selected, it must be structured correctly. Otherwise, even good data can lead to poor responses.
Therefore, context assembly focuses on:
- Ordering information logically
- Formatting content consistently
- Adding system instructions
- Managing token limits
As a result, the model receives clear, concise, and relevant context.
6. Generation Layer
At this stage, the language model generates a response using:
- The original user query
- Retrieved and assembled context
- System-level instructions
In many systems, different models may be used for different tasks. For example, one model may handle reasoning, while another performs summarization. Consequently, cost and performance can be optimized.
7. Validation and Post-Processing
Finally, enterprise-grade RAG systems rarely trust raw output directly.
Therefore, validation steps may include:
- Rule-based checks
- Confidence scoring
- Source citation enforcement
- Output formatting
As a result, responses become safer, more consistent, and more reliable.
RAG Architecture vs Traditional LLM Systems
| Aspect | Traditional LLM | RAG Architecture |
|---|---|---|
| Knowledge | Static | Dynamic |
| Accuracy | Unreliable | Grounded |
| Data access | None | External |
| Governance | Minimal | Built-in |
| Scalability | Limited | High |
Thus, RAG architecture clearly outperforms traditional approaches for real-world applications.
Common RAG Architecture Patterns
Single-Stage RAG
This is the simplest form of RAG. It retrieves documents once and generates an answer. However, it is best suited only for small-scale use cases.
Multi-Stage RAG
In contrast, multi-stage RAG introduces multiple retrieval and ranking steps. Therefore, it is widely used in enterprise systems.
Agent-Based RAG
Finally, agent-based RAG allows retrieval to occur dynamically during multi-step reasoning. As a result, complex tasks can be handled more effectively.
Engineering Challenges in RAG Architecture
Although RAG architecture is powerful, it introduces several engineering challenges.
For example:
- Increased latency due to multiple steps
- Prompt size limitations
- Ensuring data freshness
- Monitoring retrieval quality
- Evaluating end-to-end accuracy
Therefore, successful RAG systems require strong software engineering practices, not just ML expertise.
Best Practices for RAG Architecture in 2026
To build reliable systems, teams should follow these practices:
- Separate retrieval and generation logic
- Use metadata aggressively for filtering
- Limit prompt context strictly
- Validate outputs before action
- Monitor system performance continuously
As a result, RAG systems remain scalable and trustworthy.
Where RAG Architecture Is Used Today
RAG architecture is widely used across industries. For instance:
- Enterprise knowledge assistants
- Research and analysis platforms
- Customer support automation
- Compliance and policy analysis
- Internal documentation search
In each case, RAG enables AI systems to behave responsibly and accurately.
The Future of RAG Architecture
Looking ahead, RAG architecture will continue to evolve. For example, future systems will feature:
- Adaptive retrieval strategies
- Self-optimizing pipelines
- Autonomous validation loops
- Deeper workflow integration
Consequently, RAG will move from a pattern to a core AI infrastructure layer.
Final Thoughts
In conclusion, RAG architecture is the foundation of reliable generative AI systems in 2026. Rather than relying on static model knowledge, RAG connects AI reasoning to real data.
Therefore, organizations that invest in well-designed RAG architectures gain:
- Higher accuracy
- Better governance
- Lower operational risk
- Greater scalability
Ultimately, the success of modern AI systems depends less on the model itself and more on how well retrieval and generation are architected together.