
The complete guide to adopting intelligent automation without losing control of your enterprise data
If there is one hard truth in enterprise IT today, it’s this: the gap between “having data” and “using data effectively for AI” is still massive.
Most organizations are sitting on decades of information—PDFs, SharePoint files, legacy databases, CRM records, email archives—but very little of it is actually usable by modern AI systems. As Generative AI adoption accelerates in 2025 and beyond, enterprises are discovering that simply plugging a Large Language Model (LLM) into their systems does not magically unlock intelligence.
The reality is messy.
Data is fragmented. Governance is strict. Accuracy is non-negotiable.
This is why forward-thinking enterprises are moving beyond basic RAG and toward a more controlled, orchestrated architecture that combines Agentic AI, AWS Bedrock, and Apache Solr.
Together, these technologies form the foundation of what many teams now call an enterprise AI brain—one that reasons, retrieves, verifies, and acts.
The Shift: From Passive Chatbots to Agentic AI
Over the last year, most enterprise GenAI projects have revolved around chatbots. You ask a question, and the system responds with a well-written answer. While useful, this model is fundamentally passive.
Agentic AI represents a major architectural shift.
Instead of treating AI as a conversational layer, agent-based systems treat AI as a goal-driven actor. An agent does not just respond—it plans. It breaks objectives into steps, uses tools, retrieves information, evaluates results, and then decides what to do next.
In practical enterprise terms, this changes use cases dramatically:
From “Summarize this document”
To “Find the non-compliant clause in this contract, compare it with our internal SOP, flag the risk, and draft an email to legal.”
To do this reliably, an agent needs two things Agentic AI RAG architecture
Reasoning capability (provided by modern foundation models)
A trusted, permission-aware memory (provided by enterprise-grade retrieval systems)
This is where RAG and Solr become critical.
Why Apache Solr Still Matters in the Age of Vector Databases
With the rise of vector databases, many teams ask a fair question: Why use Apache Solr at all?
The answer is simple: enterprises do not live in a purely semantic world.
Vector search is powerful for finding conceptually similar content, but it often fails in high-precision environments. In industries like finance, manufacturing, healthcare, and legal, exactness matters.
If a user searches for:
A specific policy number
A contract clause ID
A part number like “XJ-900”
A purely semantic engine might return “XJ-800” because it is conceptually similar. In enterprise systems, that kind of mistake is unacceptable.
Solr excels because it enables hybrid search:
Lexical search for precision (keywords, filters, faceting)
Vector search for semantic understanding
Metadata and ACL enforcement for governance
This makes Solr uniquely suited for enterprise RAG architectures where accuracy, performance, and security must coexist.
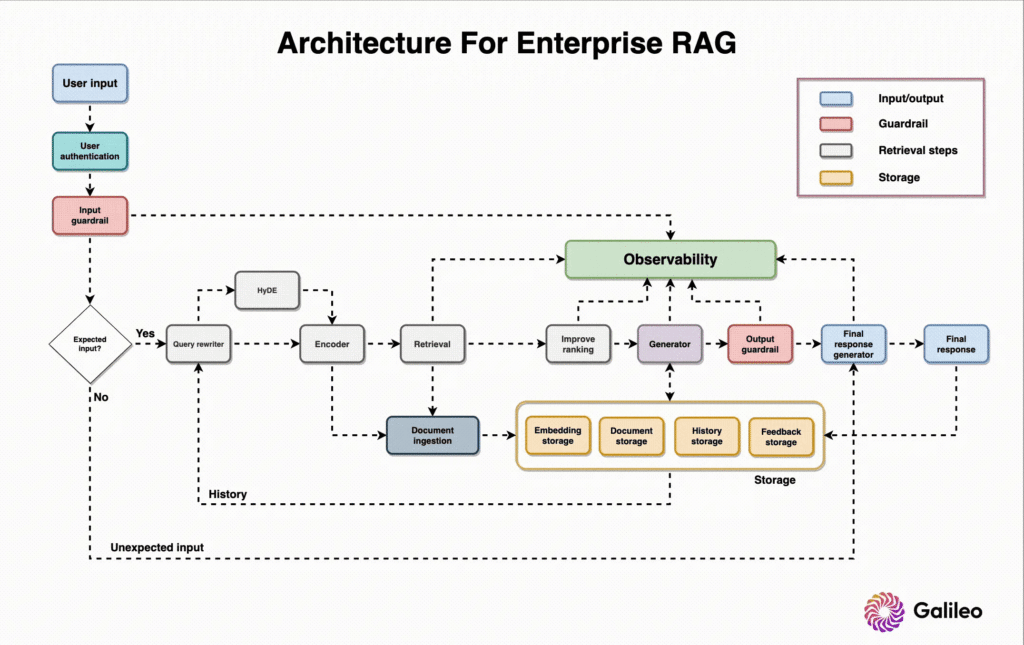
The Architecture: How RAG, Solr, and Bedrock Work Together
Retrieval-Augmented Generation (RAG) is not just a pattern—it is a safeguard.
Instead of asking an LLM to answer from its training data, RAG systems retrieve relevant enterprise documents first and inject them directly into the prompt. This grounds the model in verified, up-to-date information.
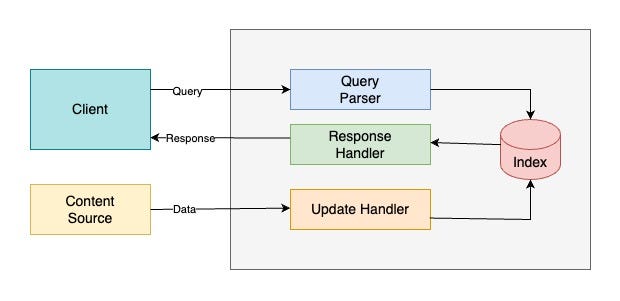
A production-grade enterprise flow typically looks like this:
1. Data Ingestion and Indexing
Raw enterprise data—PDFs, Word documents, HTML pages, emails—is ingested. Text is extracted, enriched with metadata (department, version, owner), and indexed into Solr. Vector embeddings are generated alongside traditional indexes.
2. Agentic Orchestration
When a user submits a request, the agent layer interprets intent. Using tools such as Bedrock Agents or graph-based frameworks, the agent decomposes the task into smaller steps.
3. Hybrid Retrieval
Solr is queried using both vector similarity and keyword constraints. The result is a hybrid relevance score that balances semantic meaning with exact matches and access controls.
4. Generation via Bedrock
The retrieved content is injected into a prompt and sent to a foundation model hosted on AWS Bedrock—such as Claude or Llama—ensuring data never leaves your cloud boundary.
5. Action and Automation
The system either returns a grounded response or triggers downstream workflows: updating a CRM ticket, opening a Jira issue, or escalating a compliance alert.
AWS Bedrock: Control, Choice, and Enterprise Safety
One of the biggest challenges enterprises face with GenAI is model governance. Different tasks require different trade-offs between cost, speed, and reasoning depth.
AWS Bedrock solves this by offering model choice under a unified security framework.
Enterprises can:
Use large, high-reasoning models for legal or compliance analysis
Use smaller, faster models for summarization or classification
Switch models without rewriting application logic
More importantly, Bedrock keeps enterprise data isolated from model training, which is a critical requirement for regulated industries.
The Uncomfortable Truth: Engineering Still Matters
There is a dangerous myth that GenAI systems are “plug and play.” In reality, successful enterprise AI deployments are built on strong engineering fundamentals.
Clean Data Is Non-Negotiable
No retrieval system can fix poor data quality. Bad OCR, missing metadata, and outdated documents will lead to confident but incorrect AI outputs. Enterprises must invest in robust ingestion pipelines and data hygiene.
Governance and Access Control
RAG systems must respect existing permissions. If an employee is not allowed to view a document, the AI must not retrieve it either. Solr’s mature ACL handling makes this enforceable at query time.
Evaluation and Feedback Loops
Agentic systems must be monitored. Enterprises need metrics for retrieval accuracy, response relevance, and task success rates—not just token counts.
The Real ROI: Why This Architecture Wins
When enterprises combine Agentic AI with Solr-backed RAG and Bedrock-hosted models, they address the biggest risk in GenAI adoption: hallucinations.
Instead of generating answers from probability alone, the system:
Retrieves verified data
Cites internal sources
Acts only within defined boundaries
This unlocks real business value:
Customer Support: Agents resolve issues by checking order history, warranty terms, and policy documents in real time.
Compliance and Risk: Automated scanning of thousands of documents for regulatory exposure.
Internal Knowledge: HR and IT bots that distinguish between document versions and enforce policy correctness.
Final Thoughts: From AI Experiments to Enterprise Systems
The AI industry is moving past experimentation and into implementation.
Enterprises that succeed will not be the ones chasing the largest models, but those building grounded, governed, and extensible systems. By combining Agentic AI reasoning, the structured retrieval power of Apache Solr, and the flexibility of AWS Bedrock, organizations create AI platforms that are not just impressive—but dependable.
This is how intelligent automation becomes a long-term asset rather than a short-lived demo.
If your organization is serious about modernizing its enterprise knowledge systems, this architecture offers the right balance of innovation, control, and scalability.
Agentic AI RAG architecture
Pingback: How to Become an AI Engineer in 2026 – Complete Roadmap